 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter Bot Detection
Twitter-bot detection is the process of identifying and categorizing automated accounts on Twitter.
Papers and Code
Amplification to Synthesis: A Comparative Analysis of Cognitive Operations Before and After Generative AI
May 13, 2026Cognitive operations are a rising concern in the geopolitical sphere, a quiet yet rigorous fight for public perception and decision making. While such operations have been extensively studied in the context of bot-driven amplification, the emergence of generative AI introduces a new set of capabilities that may have fundamentally altered how these operations are designed and executed. The possible evolution of cognitive operation via generative AI puts nation states vulnerable without proper mitigation strategies. To address this, we compared behavioral and linguistic coordination patterns in X (formerly Twitter) datasets from the 2016 and 2024 U.S. presidential elections. Utilizing a combined corpus of over 133,000 posts, we applied post-type distribution, semantic clustering, temporal synchrony analysis, and Jaccard-based lexical overlap measures. Findings suggest that the 2024 corpus exhibits a distinct pattern from 2016. Original content rose from 59% to 93% with retweets virtually disappeared; lexical overlap collapsed from a mean Jaccard score of 0.99 to 0.27, with posts converging on the same subject matter expressed in markedly different words; and temporal coordination shifted from pervasive cross-semantic synchrony to narratively concentrated co-occurrence. Taken together, these patterns point toward an operational logic organized around active content generation and narrative-specific targeting - characteristics consistent with generative AI involvement. These findings offer an empirical baseline for future research investigating generative AI's role in the cognitive operation pipeline, and as a practical reference point for security practitioners developing detection frameworks calibrated to the post-generative AI threat environment.
Adaptive Causal Coordination Detection for Social Media: A Memory-Guided Framework with Semi-Supervised Learning
Jan 01, 2026Detecting coordinated inauthentic behavior on social media remains a critical and persistent challenge, as most existing approaches rely on superficial correlation analysis, employ static parameter settings, and demand extensive and labor-intensive manual annotation. To address these limitations systematically, we propose the Adaptive Causal Coordination Detection (ACCD) framework. ACCD adopts a three-stage, progressive architecture that leverages a memory-guided adaptive mechanism to dynamically learn and retain optimal detection configurations for diverse coordination scenarios. Specifically, in the first stage, ACCD introduces an adaptive Convergent Cross Mapping (CCM) technique to deeply identify genuine causal relationships between accounts. The second stage integrates active learning with uncertainty sampling within a semi-supervised classification scheme, significantly reducing the burden of manual labeling. The third stage deploys an automated validation module driven by historical detection experience, enabling self-verification and optimization of the detection outcomes. We conduct a comprehensive evaluation using real-world datasets, including the Twitter IRA dataset, Reddit coordination traces, and several widely-adopted bot detection benchmarks. Experimental results demonstrate that ACCD achieves an F1-score of 87.3\% in coordinated attack detection, representing a 15.2\% improvement over the strongest existing baseline. Furthermore, the system reduces manual annotation requirements by 68\% and achieves a 2.8x speedup in processing through hierarchical clustering optimization. In summary, ACCD provides a more accurate, efficient, and highly automated end-to-end solution for identifying coordinated behavior on social platforms, offering substantial practical value and promising potential for broad application.
Bots Don't Sit Still: A Longitudinal Study of Bot Behaviour Change, Temporal Drift, and Feature-Structure Evolution
Dec 18, 2025Social bots are now deeply embedded in online platforms for promotion, persuasion, and manipulation. Most bot-detection systems still treat behavioural features as static, implicitly assuming bots behave stationarily over time. We test that assumption for promotional Twitter bots, analysing change in both individual behavioural signals and the relationships between them. Using 2,615 promotional bot accounts and 2.8M tweets, we build yearly time series for ten content-based meta-features. Augmented Dickey-Fuller and KPSS tests plus linear trends show all ten are non-stationary: nine increase over time, while language diversity declines slightly. Stratifying by activation generation and account age reveals systematic differences: second-generation bots are most active and link-heavy; short-lived bots show intense, repetitive activity with heavy hashtag/URL use; long-lived bots are less active but more linguistically diverse and use emojis more variably. We then analyse co-occurrence across generations using 18 interpretable binary features spanning actions, topic similarity, URLs, hashtags, sentiment, emojis, and media (153 pairs). Chi-square tests indicate almost all pairs are dependent. Spearman correlations shift in strength and sometimes polarity: many links (e.g. multiple hashtags with media; sentiment with URLs) strengthen, while others flip from weakly positive to weakly or moderately negative. Later generations show more structured combinations of cues. Taken together, these studies provide evidence that promotional social bots adapt over time at both the level of individual meta-features and the level of feature interdependencies, with direct implications for the design and evaluation of bot-detection systems trained on historical behavioural features.
On the efficacy of old features for the detection of new bots
Jun 24, 2025
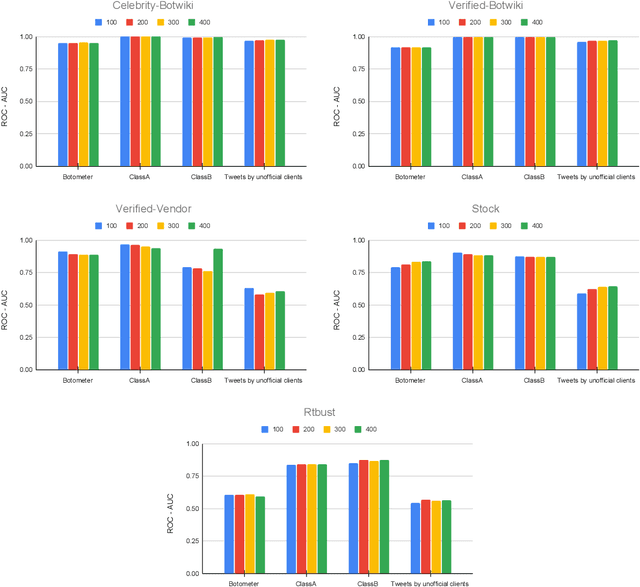
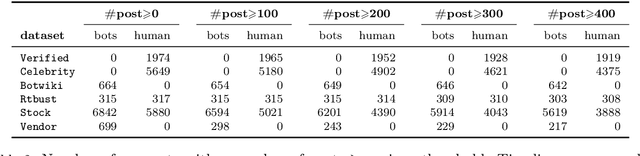

For more than a decade now, academicians and online platform administrators have been studying solutions to the problem of bot detection. Bots are computer algorithms whose use is far from being benign: malicious bots are purposely created to distribute spam, sponsor public characters and, ultimately, induce a bias within the public opinion. To fight the bot invasion on our online ecosystem, several approaches have been implemented, mostly based on (supervised and unsupervised) classifiers, which adopt the most varied account features, from the simplest to the most expensive ones to be extracted from the raw data obtainable through the Twitter public APIs. In this exploratory study, using Twitter as a benchmark, we compare the performances of four state-of-art feature sets in detecting novel bots: one of the output scores of the popular bot detector Botometer, which considers more than 1,000 features of an account to take a decision; two feature sets based on the account profile and timeline; and the information about the Twitter client from which the user tweets. The results of our analysis, conducted on six recently released datasets of Twitter accounts, hint at the possible use of general-purpose classifiers and cheap-to-compute account features for the detection of evolved bots.
* pre-print version
BotUmc: An Uncertainty-Aware Twitter Bot Detection with Multi-view Causal Inference
Mar 04, 2025Social bots have become widely known by users of social platforms. To prevent social bots from spreading harmful speech, many novel bot detections are proposed. However, with the evolution of social bots, detection methods struggle to give high-confidence answers for samples. This motivates us to quantify the uncertainty of the outputs, informing the confidence of the results. Therefore, we propose an uncertainty-aware bot detection method to inform the confidence and use the uncertainty score to pick a high-confidence decision from multiple views of a social network under different environments. Specifically, our proposed BotUmc uses LLM to extract information from tweets. Then, we construct a graph based on the extracted information, the original user information, and the user relationship and generate multiple views of the graph by causal interference. Lastly, an uncertainty loss is used to force the model to quantify the uncertainty of results and select the result with low uncertainty in one view as the final decision. Extensive experiments show the superiority of our method.
Collaborative Content Moderation in the Fediverse
Jan 10, 2025



The Fediverse, a group of interconnected servers providing a variety of interoperable services (e.g. micro-blogging in Mastodon) has gained rapid popularity. This sudden growth, partly driven by Elon Musk's acquisition of Twitter, has created challenges for administrators though. This paper focuses on one particular challenge: content moderation, e.g. the need to remove spam or hate speech. While centralized platforms like Facebook and Twitter rely on automated tools for moderation, their dependence on massive labeled datasets and specialized infrastructure renders them impractical for decentralized, low-resource settings like the Fediverse. In this work, we design and evaluate FedMod, a collaborative content moderation system based on federated learning. Our system enables servers to exchange parameters of partially trained local content moderation models with similar servers, creating a federated model shared among collaborating servers. FedMod demonstrates robust performance on three different content moderation tasks: harmful content detection, bot content detection, and content warning assignment, achieving average per-server macro-F1 scores of 0.71, 0.73, and 0.58, respectively.
Entendre, a Social Bot Detection Tool for Niche, Fringe, and Extreme Social Media
Aug 13, 2024Social bots-automated accounts that generate and spread content on social media-are exploiting vulnerabilities in these platforms to manipulate public perception and disseminate disinformation. This has prompted the development of public bot detection services; however, most of these services focus primarily on Twitter, leaving niche platforms vulnerable. Fringe social media platforms such as Parler, Gab, and Gettr often have minimal moderation, which facilitates the spread of hate speech and misinformation. To address this gap, we introduce Entendre, an open-access, scalable, and platform-agnostic bot detection framework. Entendre can process a labeled dataset from any social platform to produce a tailored bot detection model using a random forest classification approach, ensuring robust social bot detection. We exploit the idea that most social platforms share a generic template, where users can post content, approve content, and provide a bio (common data features). By emphasizing general data features over platform-specific ones, Entendre offers rapid extensibility at the expense of some accuracy. To demonstrate Entendre's effectiveness, we used it to explore the presence of bots among accounts posting racist content on the now-defunct right-wing platform Parler. We examined 233,000 posts from 38,379 unique users and found that 1,916 unique users (4.99%) exhibited bot-like behavior. Visualization techniques further revealed that these bots significantly impacted the network, amplifying influential rhetoric and hashtags (e.g., #qanon, #trump, #antilgbt). These preliminary findings underscore the need for tools like Entendre to monitor and assess bot activity across diverse platforms.
Using RL to Identify Divisive Perspectives Improves LLMs Abilities to Identify Communities on Social Media
Jun 03, 2024

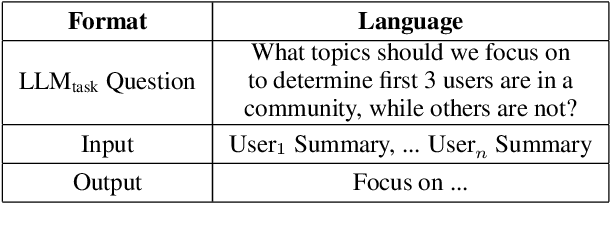
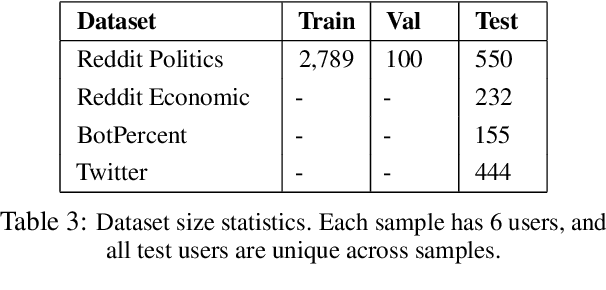
The large scale usage of social media, combined with its significant impact, has made it increasingly important to understand it. In particular, identifying user communities, can be helpful for many downstream tasks. However, particularly when models are trained on past data and tested on future, doing this is difficult. In this paper, we hypothesize to take advantage of Large Language Models (LLMs), to better identify user communities. Due to the fact that many LLMs, such as ChatGPT, are fixed and must be treated as black-boxes, we propose an approach to better prompt them, by training a smaller LLM to do this. We devise strategies to train this smaller model, showing how it can improve the larger LLMs ability to detect communities. Experimental results show improvements on Reddit and Twitter data, on the tasks of community detection, bot detection, and news media profiling.
LMBot: Distilling Graph Knowledge into Language Model for Graph-less Deployment in Twitter Bot Detection
Jul 03, 2023As malicious actors employ increasingly advanced and widespread bots to disseminate misinformation and manipulate public opinion, the detection of Twitter bots has become a crucial task. Though graph-based Twitter bot detection methods achieve state-of-the-art performance, we find that their inference depends on the neighbor users multi-hop away from the targets, and fetching neighbors is time-consuming and may introduce bias. At the same time, we find that after finetuning on Twitter bot detection, pretrained language models achieve competitive performance and do not require a graph structure during deployment. Inspired by this finding, we propose a novel bot detection framework LMBot that distills the knowledge of graph neural networks (GNNs) into language models (LMs) for graph-less deployment in Twitter bot detection to combat the challenge of data dependency. Moreover, LMBot is compatible with graph-based and graph-less datasets. Specifically, we first represent each user as a textual sequence and feed them into the LM for domain adaptation. For graph-based datasets, the output of LMs provides input features for the GNN, enabling it to optimize for bot detection and distill knowledge back to the LM in an iterative, mutually enhancing process. Armed with the LM, we can perform graph-less inference, which resolves the graph data dependency and sampling bias issues. For datasets without graph structure, we simply replace the GNN with an MLP, which has also shown strong performance. Our experiments demonstrate that LMBot achieves state-of-the-art performance on four Twitter bot detection benchmarks. Extensive studies also show that LMBot is more robust, versatile, and efficient compared to graph-based Twitter bot detection methods.
Descriptive Kernel Convolution Network with Improved Random Walk Kernel
Feb 08, 2024



Graph kernels used to be the dominant approach to feature engineering for structured data, which are superseded by modern GNNs as the former lacks learnability. Recently, a suite of Kernel Convolution Networks (KCNs) successfully revitalized graph kernels by introducing learnability, which convolves input with learnable hidden graphs using a certain graph kernel. The random walk kernel (RWK) has been used as the default kernel in many KCNs, gaining increasing attention. In this paper, we first revisit the RWK and its current usage in KCNs, revealing several shortcomings of the existing designs, and propose an improved graph kernel RWK+, by introducing color-matching random walks and deriving its efficient computation. We then propose RWK+CN, a KCN that uses RWK+ as the core kernel to learn descriptive graph features with an unsupervised objective, which can not be achieved by GNNs. Further, by unrolling RWK+, we discover its connection with a regular GCN layer, and propose a novel GNN layer RWK+Conv. In the first part of experiments, we demonstrate the descriptive learning ability of RWK+CN with the improved random walk kernel RWK+ on unsupervised pattern mining tasks; in the second part, we show the effectiveness of RWK+ for a variety of KCN architectures and supervised graph learning tasks, and demonstrate the expressiveness of RWK+Conv layer, especially on the graph-level tasks. RWK+ and RWK+Conv adapt to various real-world applications, including web applications such as bot detection in a web-scale Twitter social network, and community classification in Reddit social interaction networks.